Introduction
Extracting structured information from web pages remains a challenging task in natural language processing.
Regular transformers architecture are not designed to encode hierarchical information. Each token is connected to every tokens in the input sequence, regardless of their position (even though there are a few mechanisms to introduce positional information, such as positional encoding).
In a webpage, information is highly structured. The HTML represents a tree, with each node having a parent and potential siblings and children. This makes that some nodes might be semantically connected while relatively far away from each other if we consider only the number of tokens between them.
Take the following example, from Betclic:

And the corresponding HTML code:
<div class="list_content">
<sports-tile routerlinkactive="active-link" class="list_item">
<div class="list_itemWrapper" id="block-link-0">
<div class="list_itemStart">
<span class="list_itemImg icons icon_sport_football"></span>
<span class="list_itemImg flagsIconBg is-EU"></span>
</div>
<div class="list_itemContent">
<div class="list_itemTitle"> Top Football Européen </div>
</div>
</div>
</sports-tile>
<sports-tile routerlinkactive="active-link" class="list_item">
<div class="list_itemWrapper" id="block-link-3453">
<div class="list_itemStart">
<span class="list_itemImg icons icon_sport_football"></span>
<span class="list_itemImg flagsIconBg is-EU"></span>
</div>
<div class="list_itemContent">
<div class="list_itemTitle"> Ligue Europa </div>
</div>
</div>
</sports-tile>
<sports-tile routerlinkactive="active-link" class="list_item">
<div class="list_itemWrapper" id="block-link-28946">
<div class="list_itemStart">
<span class="list_itemImg icons icon_sport_football"></span>
<span class="list_itemImg flagsIconBg is-EU"></span>
</div>
<div class="list_itemContent">
<div class="list_itemTitle"> Ligue Conférence </div>
</div>
</div>
</sports-tile>
<sports-tile routerlinkactive="active-link" class="list_item">
<div class="list_itemWrapper" id="block-link-88">
<div class="list_itemStart">
<span class="list_itemImg icons icon_sport_football"></span>
<span class="list_itemImg flagsIconBg is-DK"></span>
</div>
<div class="list_itemContent">
<div class="list_itemTitle"> Danemark Superliga </div>
</div>
</div>
</sports-tile>
<sports-tile routerlinkactive="active-link" class="list_item">
<div class="list_itemWrapper" id="block-link-114">
<div class="list_itemStart">
<span class="list_itemImg icons icon_sport_tennis"></span>
<span class="list_itemImg flagsIconBg is-ES"></span>
</div>
<div class="list_itemContent">
<div class="list_itemTitle"> Barcelone ATP </div>
</div>
</div>
</sports-tile>
<sports-tile routerlinkactive="active-link" class="list_item">
<div class="list_itemWrapper" id="block-link-4684">
<div class="list_itemStart">
<span class="list_itemImg icons icon_sport_football"></span>
<span class="list_itemImg flagsIconBg is-SA"></span>
</div>
<div class="list_itemContent">
<div class="list_itemTitle"> Arabie Saoudite PL </div>
</div>
</div>
</sports-tile>
</div>
One can ask a webpage to return all the league names, which are semantically connected. However, even though the names “Top Football Européen” and “Arabie Saoudite PL” are many tokens away from each other, they are siblings. So if we could leverage the HTML graph information, they would be much closer.
Fortunately for us, researchers have already worked on algorithms using sequence modeling to achieve state-of-the-art performance in web extraction tasks, releasing Webformers. This article explores how Webformers works, its architecture, its limitations.
How
Webformers stands apart from traditional approaches by encoding HTML, target fields, and text sequences within a unified transformer model.
The key innovation lies in how it designs specialized HTML tokens for each DOM node, embedding representations from neighboring tokens through graph attention mechanisms, while constructing rich attention patterns between HTML and text tokens.
Key contributions
The Webformers approach makes two significant contributions to the field:
- Structure-aware information extraction that integrates web HTML layout through graph attention mechanisms
- Rich attention mechanisms for embedding representations among different token types, enabling efficient encoding of long sequences and empowering zero-shot extraction capabilities
Problem definition
To understand how Webformers functions, we need to define the problem it aims to solve. The web document is processed into. Let us give the authors’ notations:
- $T = (t_1, t_2, …, t_k)$ the text sequence from the web document
- $t_i$ represents the $i\text{-th}$ text node on the web
- $k$ is the total number of text nodes with $t_i = (w_{i_1}, w_{i_2}, …, w_{i_{n_i}})$ as its $n_i$ words/tokens
- note that the ordering of the text nodes does not matter in this model
- $G = (V, E)$ the DOM tree of the HTML
- $V$ is the set of DOM nodes in the tree
- $E$ is the set of edges
- the $k$ text nodes are connected in this DOM representation
The goal of structured information extraction is that given a set of target fields $F = (f_1, …, f_m)$ to extract their corresponding text information from the web document.
For example, from a text field “date” we expect the text span “Dec 13” from the web document.
The problem is defined as finding the best text span $\bar{s_j}$ for each field $f_j$ given the web document $T$ and $G$:
$$ \bar{s_j} = \argmax_{b_j, e_j} Pr(w_{b_j}, w_{e_j} | f_j, T, G) $$
where $b_j$ and $e_j$ are the begin and end offsets of the extracted text span in the web document for text field $f_j$.
Architecture
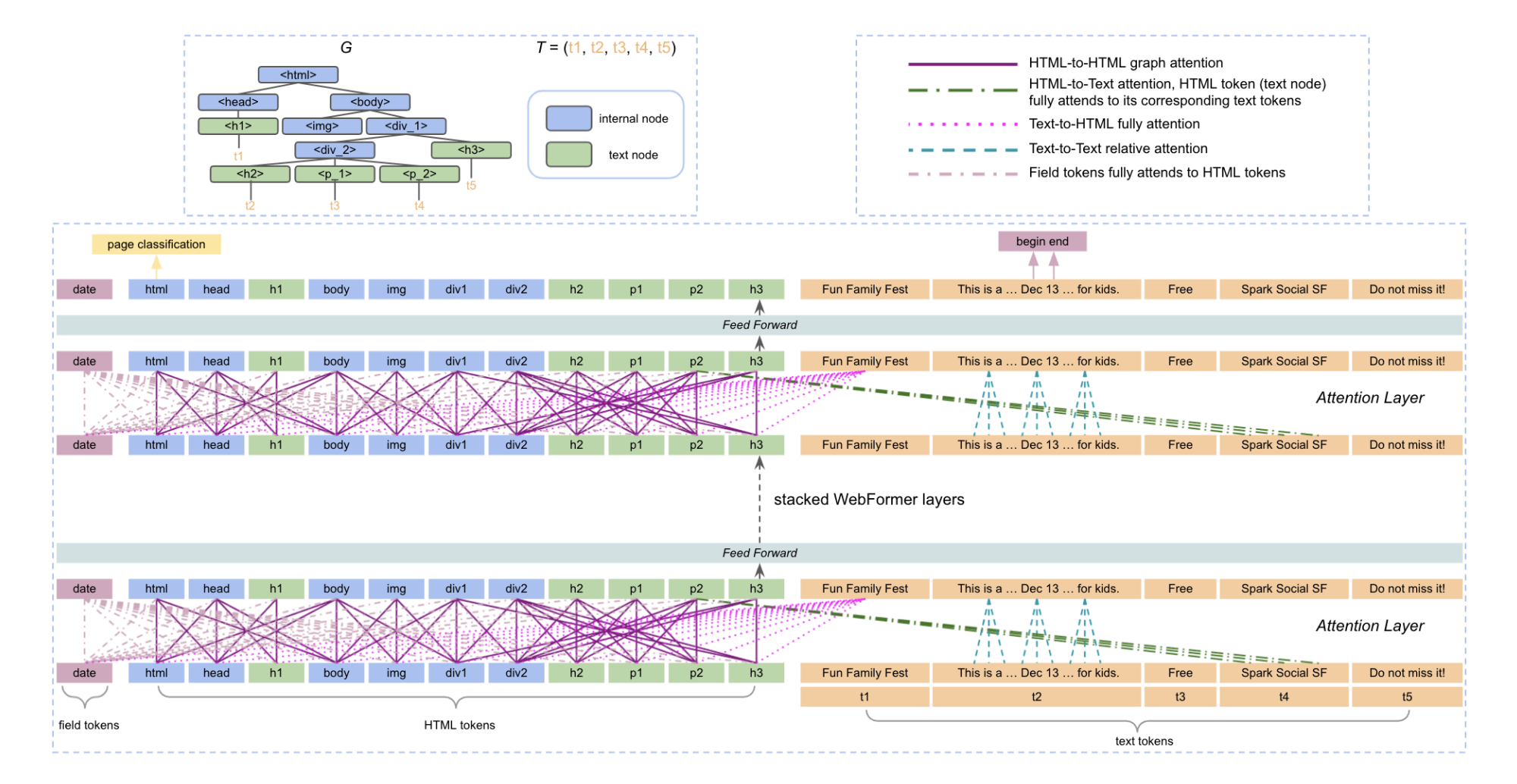
WebFormer consists of three main components:
- the input layer
- contains the construction of the input tokens of webformer as well as their embeddings, including the field token, the HTML tokens from DOM tree $G$ and the text tokens from the text sequence $T$
- the webformer encoder
- this is the main block
- encodes the input sequence with rich attention patterns, including HTML to HTML (H2H), HTML to Text (H2T), Text to HTML (T2H) and Text to Text (T2T) attentions as detailed below
- the output layer
- the text span corresponding to the field is computed based on the encoded field-dependent text embeddings
Input layer
The paper introduces 3 new token types:
- Field token
- A set of field tokens are used to represent the text field to be extracted such as title, company, base salary… for a job page
- By jointly encoding the text field, the authors are able to construct a unique model across all text fields
- HTML token
- Each node in the DOM tree $G$ including both internal nodes (non text) and text nodes corresponds to a HTML token
- The embedding of a HTML token can be viewed as a summarization of the sub-tree rooted by this node
- The token represents the full doc
- The token summarizes the text sequence $t_4$
- Text token
- The commonly used word representation in natural language models.
In the input layer, every token is converted into a $d$-dimensional embedding vector.
For field and text embedding, their final embedding is constructed by concatenating a word embedding and a segment embedding.
For HTML token embedding, they are formulated by concatenating a tag embedding and a segment embedding
The segment embedding is added to indicate which type the token belongs to (field, HTML, text) and the tag embedding represents different HTML tag of the DOM nodes.
Encoder
The encoder consists of $L$ identical contextual layers plus one feed-forward layer. It defines several attention patterns:
- HTML-to-HTML
- Compute the attention weights between HTML tokens
- They seem to use some kind of graph attention (source 43 in the paper)
- For example is connected to:
- Itself
- Its parent
- Its children and
- Its siblings
- HTML-to-Text
- Computed for the text nodes in the HTML to update their contextual embeddings
- For example, the HTML token is connected to the tokens in the t4 sequence
- Text-to-HTML
- Text tokens are connected with every HTML tokens so they absorb the high-level representation of the web document
- Text-to-Text
- Regular attention mechanism
- Text tokens are only connected to their neighbors (the other text tokens inside the same tag and within a radius $r$)
- Field token attention
- (As a reminder, the field tokens represent the data to be extracted (price, article title…))
- The field token is connected to every HTML tokens
- The authors tried to connect the field token to every text tokens on top of HTML tokens but it did not improved the quality of the extraction
- Overall attention
- Compute the final token representation based on the above attention patterns
- For example the text token representation is the combination of the text to text representation + the text to html representation
Output layer
The output layer extracts the final text span for each field from the text tokens using a softmax function on the output embeddings to generate probabilities for the beginning and ending indices.
Limitations
Despite its advancements, Webformers has two main limitations:
- Single object focus: The model is designed for pages where each target field has a single text value. For multiple objects, the authors recommend using repeated patterns methods.
- No rendered page consideration: The model does not take into account the visually rendered page (OCR), focusing solely on the HTML structure.
Results
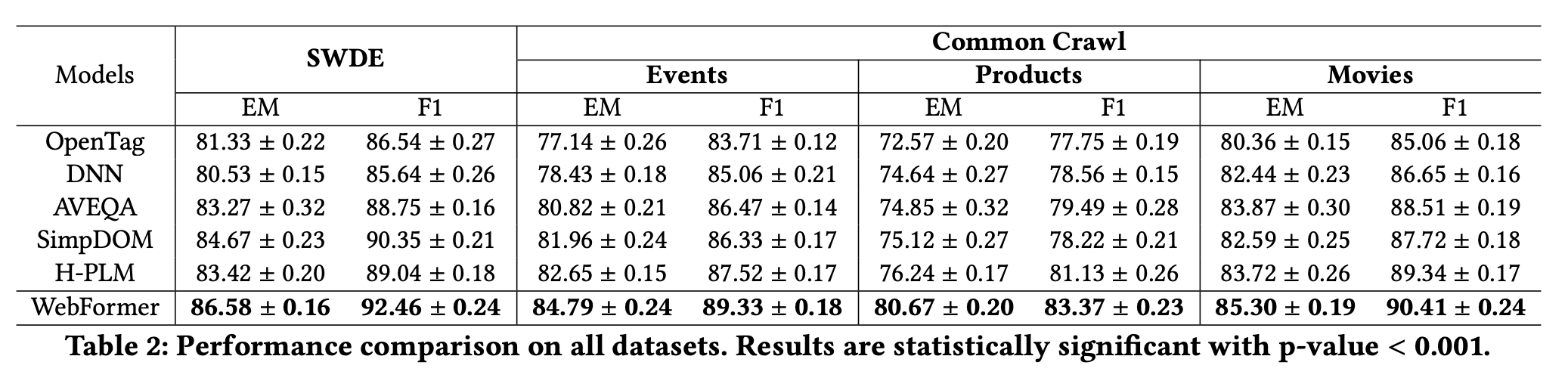
Webformers achieves state-of-the-art performance in structured information extraction from web documents. Its ability to leverage the HTML structure through graph attention mechanisms and its rich attention patterns between different token types enable more accurate and efficient extraction compared to previous approaches.
The model’s architecture allows for zero-shot extraction capabilities, making it particularly valuable for applications requiring information extraction from previously unseen web page structures.
Conclusion
Webformers represents a significant advancement in structured information extraction from web documents. By integrating HTML structure through graph attention and implementing rich attention patterns, it achieves superior performance in web extraction tasks. While limitations exist, the approach opens new possibilities for more accurate and efficient information extraction from the web.
As web content continues to grow exponentially, technologies like Webformers will become increasingly important for automated information extraction and knowledge building from web sources.
At lightpanda.io, we work on researching and providing developers with the best browser, made for machine and AI. Integrating AI features in a web processing pipeline needs to be consistent and reliable. Webformer gives us a powerful base to understand content coming out of the browser, and plugging other components into it.
Resources
- The paper: https://arxiv.org/abs/2202.00217
- The Github repository: https://github.com/xrr233/Webformer