Nemotron: Advancing Tool-Calling LLMs with Rule-Based Reinforcement Learning 🤖
Large Language Models (LLMs) are becoming increasingly powerful, and their ability to interact with external tools and APIs significantly expands their capabilities. Nvidia’s Nemotron paper introduces an innovative approach to training LLMs for more effective tool use, focusing on a rule-based reinforcement learning (RL) pipeline. This method aims to overcome the common hurdle of requiring large, meticulously curated datasets, allowing models to learn optimal tool-calling strategies more autonomously.
Why Nemotron
Improving an LLM’s proficiency in using external tools typically falls into two categories:
- Enhancing core LLM capabilities: This involves techniques like Supervised Fine-Tuning (SFT) or reinforcement learning, which directly modify the model’s internal parameters.
- Optimizing prompting strategies: This explores how to best instruct the LLM to use tools effectively through carefully designed prompts.
Both avenues heavily depend on high-quality, curated data. Collecting and preparing such data, especially for complex, multi-step tasks involving multiple tool interactions, is a significant bottleneck. It’s often time-consuming and expensive.
The Nemotron paper, much like the Deepseek R1 project, demonstrates the potential of a simpler, rule-based RL training pipeline. By defining rewards based solely on the correctness of the answer and the format of the output, models can discover effective strategies on their own, reducing the dependency on manually curated datasets.
Core Concepts
Nemotron’s approach leverages several key ideas:
- SFT Tool-Calling: While SFT is a common method for initially teaching models tool use, Nemotron builds upon this by applying RL for further refinement.
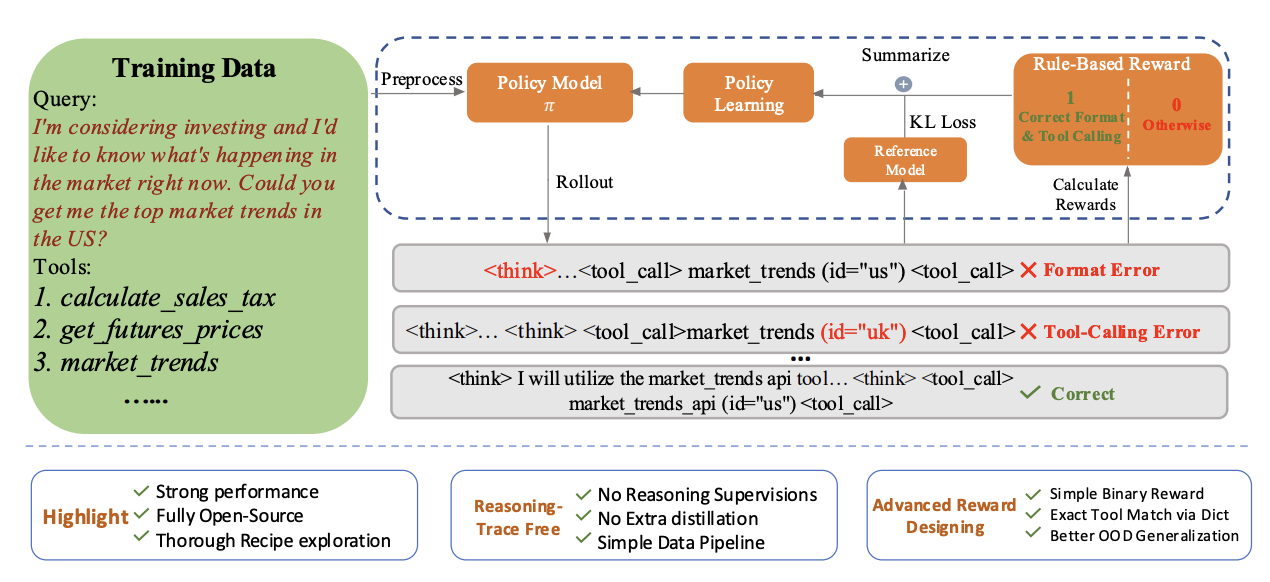
- Binary Reward Function: The learning signal is straightforward – the model receives a reward of 1 if its output is entirely correct (both in format and tool usage) and 0 otherwise. This clear-cut feedback simplifies the reward mechanism.
- GRPO (Generalized Reinforcement Policy Optimization): This specific RL algorithm is used to optimize the LLM’s policy based on the rewards received.
- Rule-Based RL: This is the cornerstone of the approach. The reward mechanism isn’t based on complex, learned reward models but on predefined rules:
- Format of the answer: The model is asked to structure its reasoning process within
<think></think>tags and its tool calls within<tool_call></tool_call>tags. - Correctness of the answer itself: The actual tool selected and the arguments provided must be accurate.
- Format of the answer: The model is asked to structure its reasoning process within
Problem Formulation
Consider an LLM and a set of available external tools, denoted as:
$$ \mathcal{Z} = \left\{ z_i \right\}^I_{i = 1} $$that the LLM can use.
Each tool can be represented as a 3-tuple $(n_i, d_i, k_i)$ being:
- $n_i$ the tool’s name
- $d_i$ the tool’s description
- $k_i$ the tool’s arguments
At each decision step $t$, the LLM receives both the historical context $c_t$ and the set of tools it has access to $\tilde{\mathcal{Z}}$ and decides the next action:
$$ \pi(c_t, \tilde{\mathcal{Z}}) \to a_t, a_t \in \mathcal{Z} $$Given the historical context $c_t$ and the set of tools $\mathcal{Z}$, the model generates a set of candidates responses $[O^1, O^2, ..., O^N]$ where each $O^i \in \mathcal{O}$. Here $\mathcal{O}$ denotes the space of possible output responses comprising:
- textual reasoning
- associated action $a_n$
These responses are then evaluated using a reward function yielding a reward set $ \left\{ r_1, r_2, ..., r_N \right\} $ . The policy $\pi_{\theta}$ is then optimized using GRPO:
$$ \mathcal{L}_{\text{GRPO}}(\theta) = \mathbb{E}_{(c_t, \mathcal{Z})}\mathbb{E}_{O^i \sim \mathcal{O}} [\min (\rho_i A_i, \text{clip}(\rho_i, 1 - \epsilon, 1 + \epsilon)A_i) = \beta \text{D}_{\text{KL}}(\pi_{\theta}||\pi_{\text{old}})] $$Where
$$ \rho_i = \frac{\pi_{\theta}(O^i | c_t, \mathcal{Z})}{\pi_{\text{old}}(O^i | c_t, \mathcal{Z})} $$And
$$ A_i = \frac{r_i - \text{mean}(r_1, r_2, ..., r_N)}{\text{std}(r_1, r_2, ..., r_N)} $$And $\epsilon$ and $\beta$ are hyperparameters.
Data Preparation
The research utilized existing datasets for tool-calling tasks:
- xLAM: Available on Hugging Face (
Salesforce/xlam-function-calling-60k). - ToolACE: Available on Hugging Face (
Team-ACE/ToolACE).
Both datasets offer synthetic tool-calling trajectories, including single-turn and multi-turn interactions. However, since these datasets are often generated by other LLMs, they can contain inconsistencies and unstructured formats. This makes them unsuitable for direct use in the GRPO training pipeline, which requires precise evaluation.
Therefore, a crucial preprocessing step was implemented:
- Filtering: Samples with invalid tool calls were removed. This specifically targeted instances where the tool called was not actually present in the provided list of candidate tools for that sample.
- Parsing and Validation: Both the candidate tool calls and the ground truth tool calls were parsed as JSON objects. Trajectories that failed this parsing step (indicating malformed data) were discarded.
The Thinking Template
To facilitate the rule-based reward system, a specific output format was enforced.
- The set of available tools is defined for the model between
<tools>and</tools>tags. - The model is then required to output its reasoning or thinking process enclosed within
<think>and</think>tags. - Finally, any tool calls must be outputted between
<tool_call>and</tool_call>tags. The model can make multiple tool calls, formatted as a list.
This structured output allows for programmatic checking of the model’s adherence to the desired format and simplifies the extraction of tool calls for evaluation.

Reward Modeling
The authors designed a reward system that checks two main aspects:
- Correct tool’s name.
- Correct tool’s arguments.
- Correctness of the reasoning format.
Format Checking
This ensures the model follows the specified structural conventions. Specifically, it verifies that the reasoning and tool call(s) are correctly enclosed within the <think></think> and <tool_call></tool_call> tags, respectively.
Tool-Calling Checking
This component assesses the accuracy of the actual tool invocation. The tool call output (within the <tool_call> tags) is parsed, typically as dictionaries. This allows for an exact match against the ground truth:
- The name of the called tool must match the expected tool.
- All required arguments must be present and correct.
Binary Reward Definition
Based on these checks, a simple binary reward is assigned:
$$ \left\{\begin{matrix} 1 \text{ if } \texttt{FormatCorrect}(O_t) \wedge \texttt{ToolCallMatch}(a_t, a_t^*) \\ 0 \text{ otherwise} \end{matrix}\right. $$Here, Ot is the model’s output at step t, at is the tool call made by the model, and at∗ is the ground truth (correct) tool call. The model only gets a positive reward if both the format is correct AND the tool call matches the ground truth.
Key Questions Answered
This research directly addresses two important questions:
- Can rule-based RL be applied to train tool-calling models?
- Yes. The Nemotron paper successfully demonstrates that a rule-based RL pipeline, using a binary reward based on output format and tool call accuracy, can effectively train LLMs for tool use.
- How should such an RL pipeline be designed?
- The pipeline should involve:
- A clear thinking template to structure model output.
- A binary reward function that checks both format adherence and tool call correctness (name and arguments).
- An appropriate RL algorithm like GRPO to optimize the model’s policy.
- Careful data preprocessing to ensure the training data, even if initially synthetic, is clean and consistently formatted for reliable reward calculation.
- The pipeline should involve:
Superiority of this approach
The main advantage of Nemotron’s rule-based RL strategy is its potential to reduce the heavy reliance on meticulously curated datasets. By allowing the model to learn from relatively simple, rule-based feedback, researchers can sidestep some of the most labor-intensive parts of training advanced LLMs. This echoes the success of systems like Deepseek R1, which also benefited from rule-based reward mechanisms, enabling models to discover effective strategies more autonomously.
My 2 cents
This work hints at broader trends in AI development:
- Rise of Synthetic Environments: The success of rule-based RL suggests a future where more training occurs in synthetic environments. In these controlled settings, agents can perform tasks, receive clear feedback, and improve iteratively, much like DeepMind’s AlphaZero learned to master games.
- Generality of Reinforcement Learning: RL is a highly general framework. It can, in principle, encapsulate approaches like supervised fine-tuning (SFT) but without the stringent need for perfectly curated, human-annotated data. This reduces the risk of introducing human biases inherent in manual data creation.
- Consolidated Frameworks: We will likely see the AI community gravitate towards more consolidated RL frameworks and invest in developing diverse and robust environments where AI agents can be pretrained or continually improved in isolation before being deployed in real-world scenarios.
Conclusion
Nvidia’s Nemotron paper offers a promising direction for developing more capable and autonomous tool-using LLMs. By employing a rule-based reinforcement learning approach with a binary reward system and the GRPO algorithm, it demonstrates a path to reduce the dependency on extensive, manually curated datasets, potentially accelerating the development of sophisticated AI agents.
Sources
- Paper: Nemotron: A Rule-based Reinforcement Learning Framework for Tool-calling Language Models - https://arxiv.org/abs/2505.00024
- Code: NVlabs/Tool-N1 on GitHub - https://github.com/NVlabs/Tool-N1